Overview¶
Following the de facto standard of OpenAI Gym, we build a universe of market environments for data-driven financial reinforcement learning, namely, FinRL-Meta. We keep the following design principles.
1. Supported trading tasks:¶
We have supported and achieved satisfactory trading performance for trading tasks such as stock trading, cryptocurrency trading, and portfolio allocation. Derivatives such as futures and forex are also supported. Besides, we have supported multi-agent simulation and execution optimizing tasks by reproducing the experiment in other published papers.
2. Training-testing-trading pipeline:¶
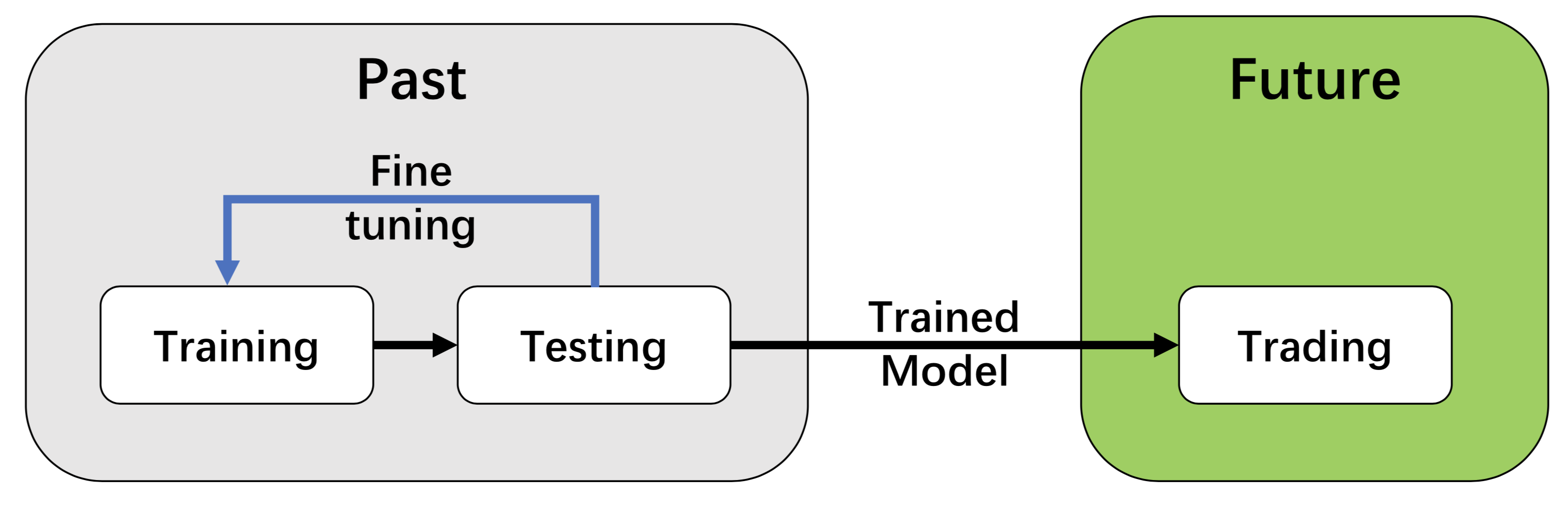
We employ a training-testing-trading pipeline that the DRL approach follows a standard end-to-end pipeline. The DRL agent is first trained in a training environment and then fined-tuned (adjusting hyperparameters) in a validation environment. Then the validated agent is tested on historical datasets (backtesting). Finally, the tested agent will be de- ployed in paper trading or live trading markets.
This pipeline solves the information leakage problem because the trading data are never leaked when training/tuning the agents.
Such a unified pipeline allows fair comparisons among different algorithms and strategies.
3. DataOps for data-driven financial reinforcement leanring¶
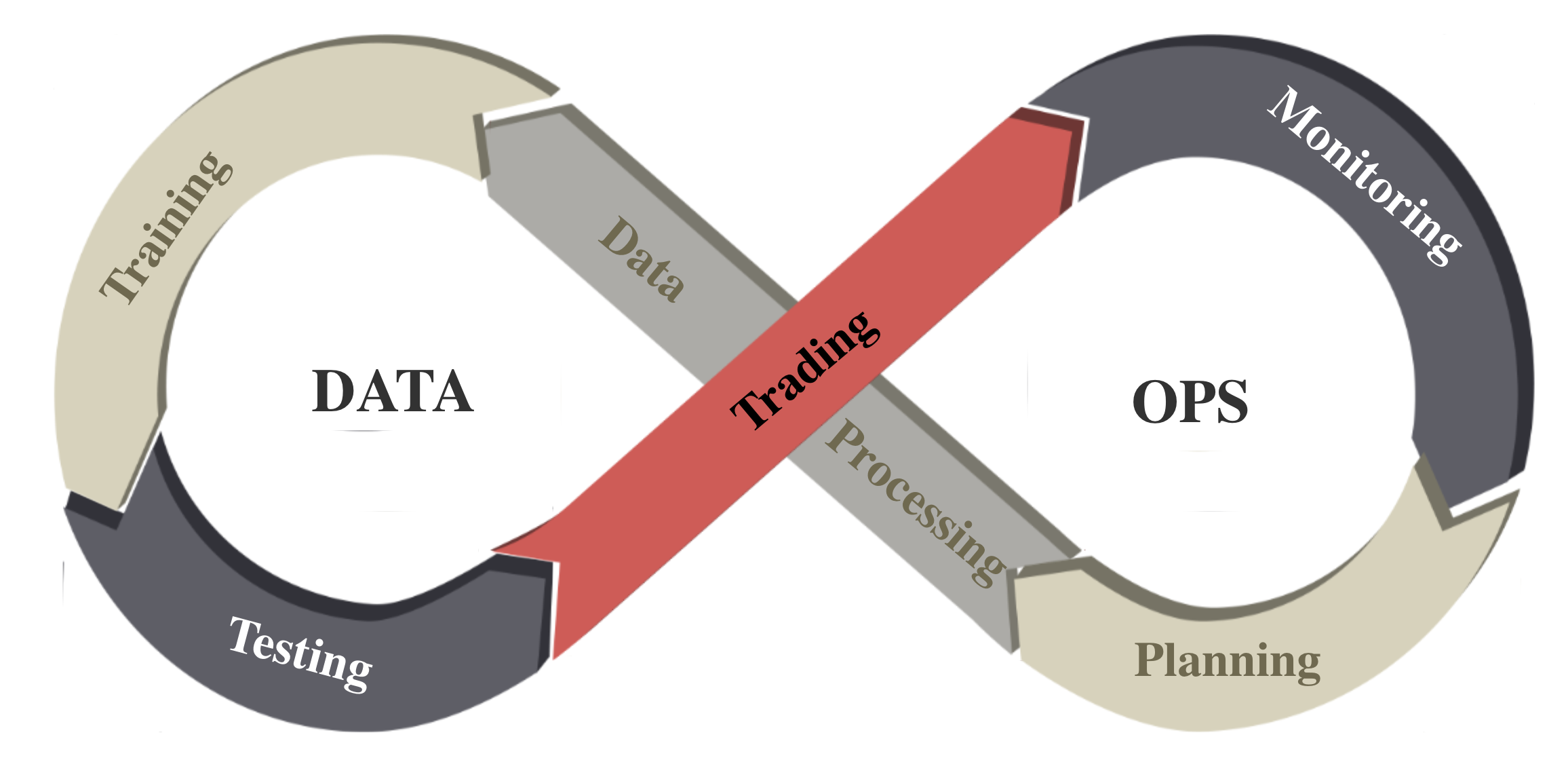
We follow the DataOps paradigm in the data layer, as shown in the figure above. First, we establish a standard pipeline for financial data engineering, ensuring data of different formats from different sources can be incorporated in a unified RL framework. Second, we automate this pipeline with a data processor, which can access data, clean data and extract features from various data sources with high quality and efficiency. Our data layer provides agility to model deployment.
4. Layered structure and extensibility¶
We adopt a layered structure for RL in finance, which consists of three layers: data layer, environment layer, and agent layer. Each layer executes its functions and is relatively independent. Meanwhile, layers interact through end-to-end interfaces to implement the complete workflow of algorithm trading, achieving high extensibility. For updates and substitutes inside the layer, this structure minimizes the impact on the whole system. Moreover, user-defined functions are easy to extend, and algorithms can be updated fast to keep high performance.
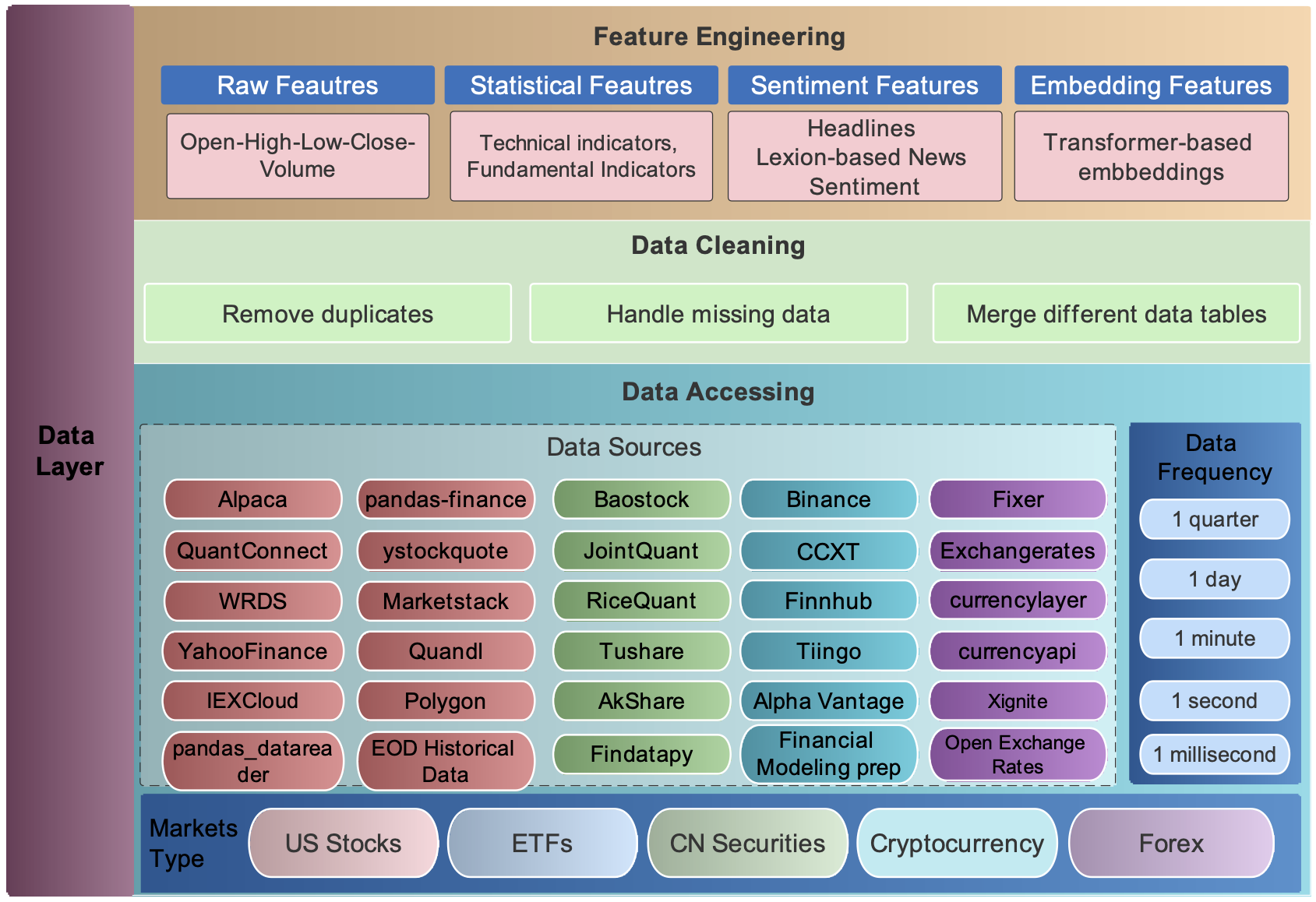
5. Plug-and-play¶
In the development pipeline, we separate market environments from the data layer and the agent layer. Any DRL agent can be directly plugged into our environments, then will be trained and tested. Different agents can run on the same benchmark environment for fair comparisons. Several popular DRL libraries are supported, including ElegantRL, RLlib, and SB3.