Background¶
Dataset: Financial Big Data¶
FinRL-Meta provides multiple datasets for financial reinforcement learning. Stepping into the era of internet, the speed of information exchange has an exponential increment. Along with that, the amount of data also explodes into an incredible number, which generates the new concept “big data”.
As its data refreshing minute-to-second, finance is one of the most typical domains that big data imbeded in. Financial big data, as a new popular field, gets more and more attention by economists, data scientists, and computer scientists.
In academia, scholors use financial big data to explore more complex and precise understanding of market and economics. While industries use financial big data to refine their analytical strategies and strengthen their prediction models. Realizing the potential of this solid background, AI4Finance community started FinRL-Meta to serve for various needs by researchers and industries.
For datasets, FinRL-Meta has standardized flow of data extraction and cleaning for more than 30 different data sources. The purpose of providing the data pulling tool instead of a fixed dataset is better corresponding to the fast updating property of financial market. The dynamic construction can help users grip data according to their own requirement.
Benchmark¶
FinRL-Meta provides multiple benchmarks for financial reinforcement learning.
FinRL-Meta benchmarks work in famous papers and projects, covering stock trading, cyptocurrency trading, portfolio allocation, hyper-parameter tuning, etc. Along with that, there are Jupyter/Python demos that help users to test or design new strategies.
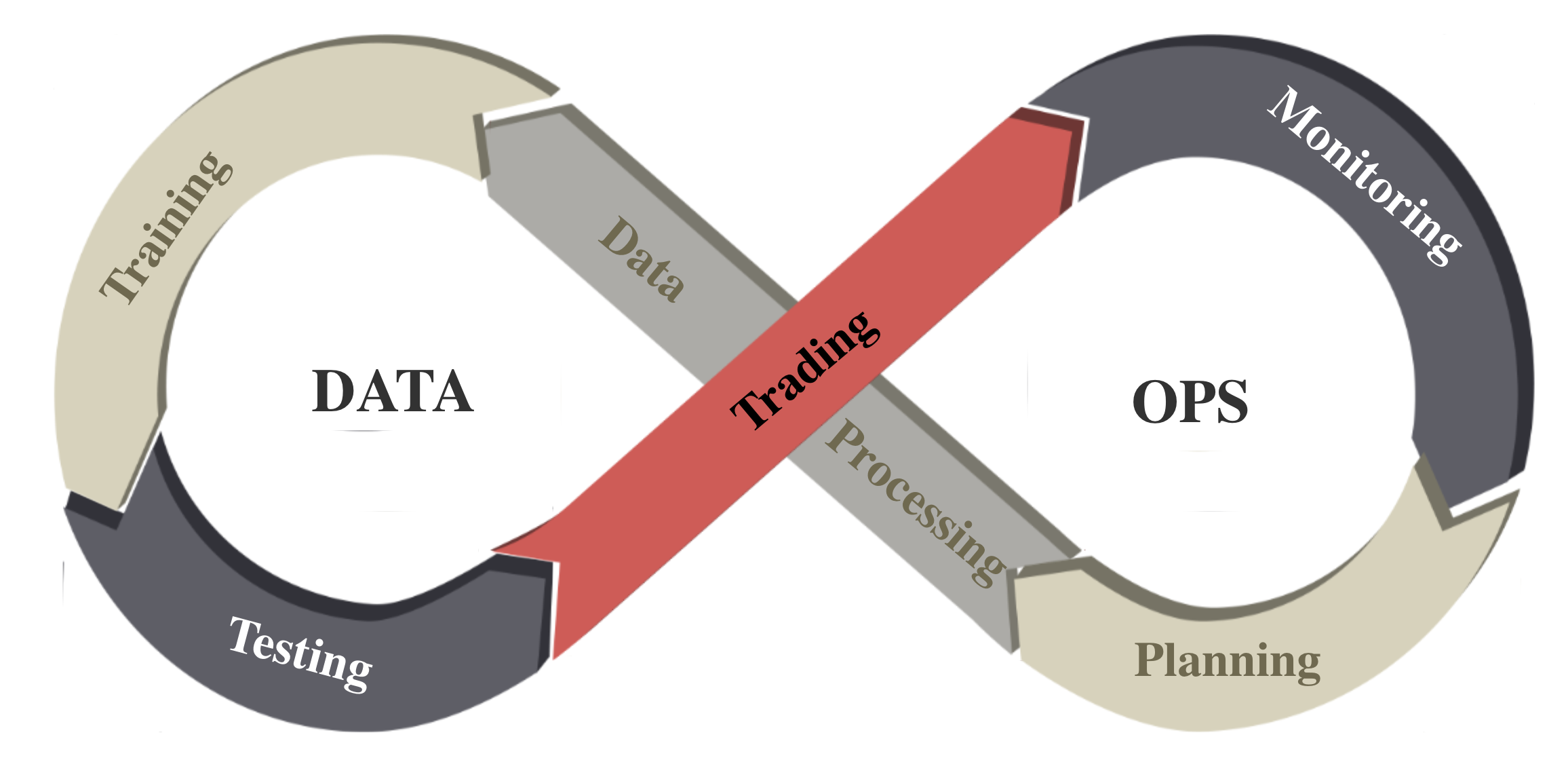
DataOps¶
DataOps applies the ideas of lean development and DevOps to the data analytics field. DataOps practices have been developed in companies and organizations to improve the quality of and efficiency of data analytics. These implementations consolidate various data sources, unify and automate the pipeline of data analytics, including data accessing, cleaning, analysis, and visualization.
However, the DataOps methodology has not been applied to financial reinforcement learning researches. Most researchers access data, clean data, and extract technical indicators (features) in a case-by-case manner, which involves heavy manual work and may not guarantee the data quality.
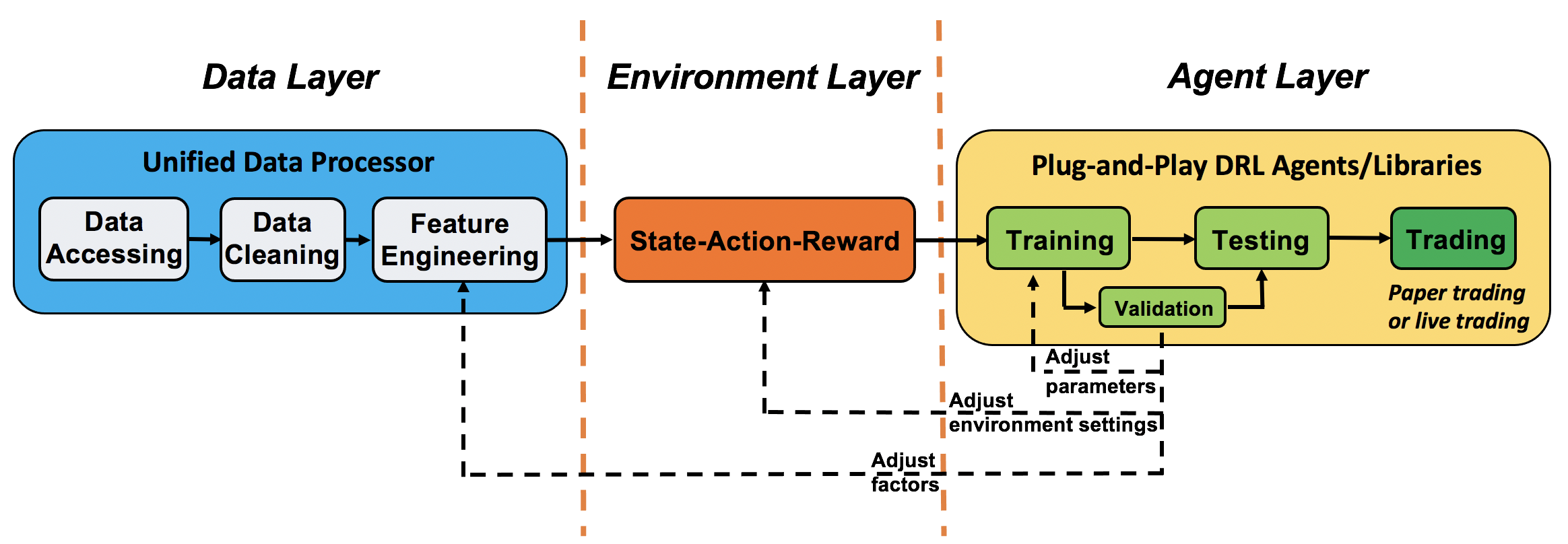
To deal with financial big data (usually unstructured), we follow the DataOps paradigm and implement an automatic pipeline in the following figure: task planning, data processing, training-testing-trading, and monitoring agents’ performance. Through this pipeline, we continuously produce DRL benchmarks on dynamic market datasets.
We follow the DataOps paradigm in the data layer.
we establish a standard pipeline for financial data engineering in RL, ensuring data of different formats from different sources can be incorporated in a unified framework.
we automate this pipeline with a data processor, which can access data, clean data, and extract features from various data sources with high quality and efficiency. Our data layer provides agility to model deployment.
we employ a training-testing-trading pipeline. The DRL agent first learns from the training environment and is then validated in the validation environment for further adjustment. Then the validated agent is tested in historical datasets. Finally, the tested agent will be deployed in paper trading or live trading markets. First, this pipeline solves the information leakage problem because the trading data are never leaked when adjusting agents. Second, a unified pipeline allows fair comparisons among different algorithms and strategies.