Overview¶
Following the de facto standard of OpenAI Gym, we build a universe of market environments for data-driven financial reinforcement learning, namely, FinRL-Meta. We keep the following design principles.
1. Layered structure¶
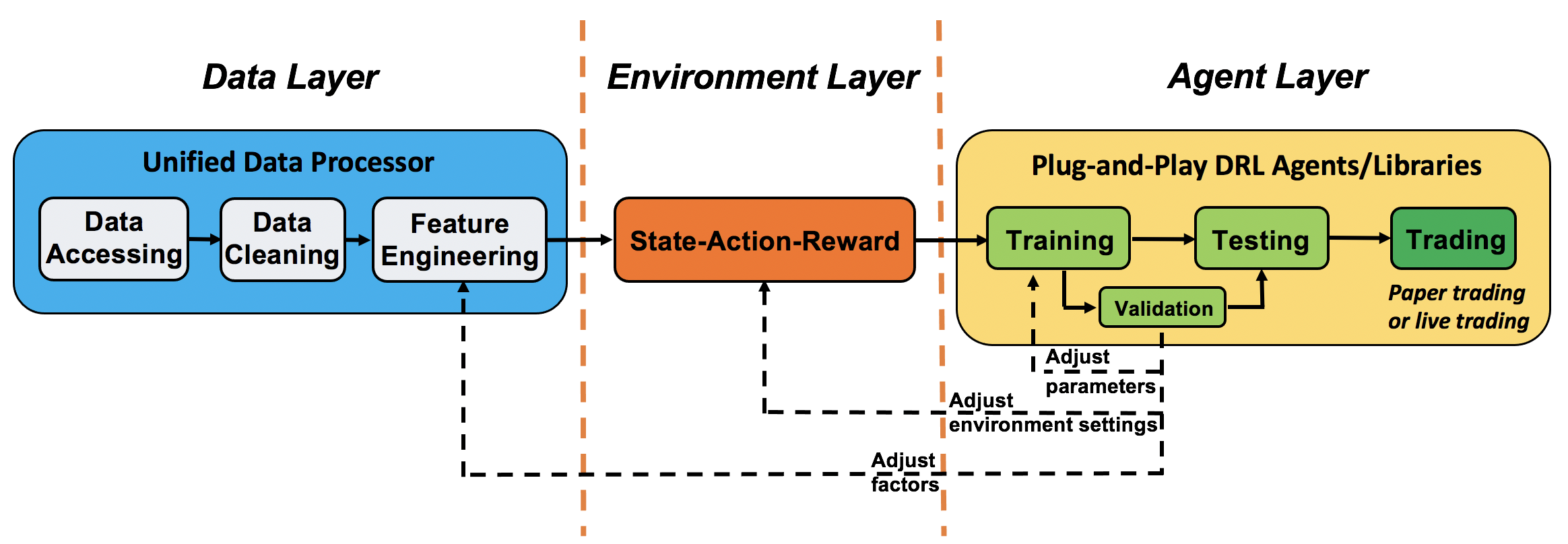
We adopt a layered structure for RL in finance, which consists of three layers: data layer, environment layer, and agent layer. Each layer executes its functions and is relatively independent. There are two main advantages:
Transparency: layers interact through end-to-end interfaces to implement the complete workflow of algorithm trading, achieving high extensibility.
Modularity: Following the APIs between layers, users can easily customize their own functions to substitute default functions in any layer.
2. DataOps Paradigm¶
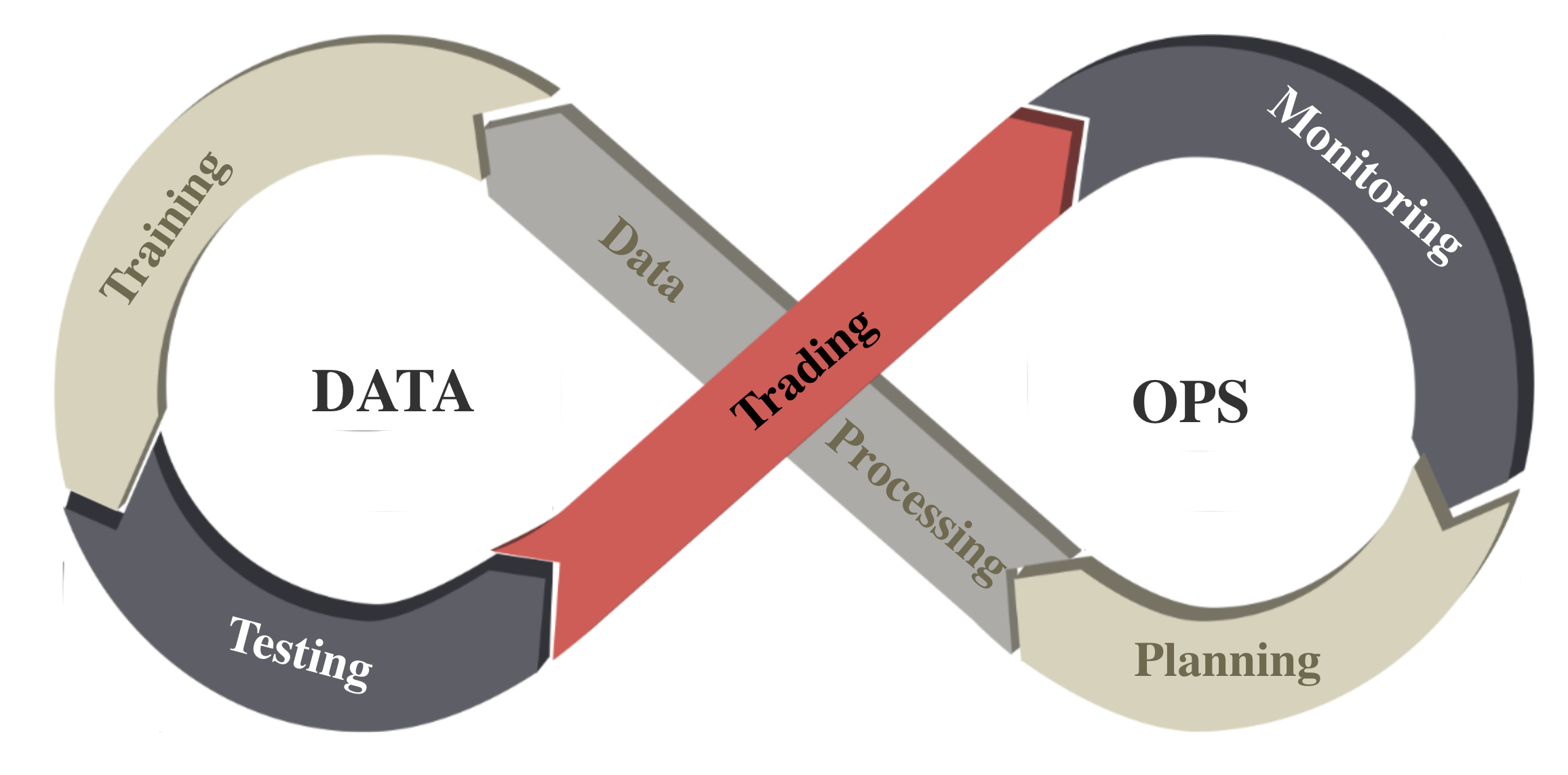
DataOps paradigm is a set of practices, processes and technologies that combined: automated data engineering & agile development. It helps reduce the cycle time of data engineering and improves data quality. To deal with financial big data, we follow the DataOps paradigm and implement an automatic pipeline:
Task planning, such as stock trading, portfolio allocation, cryptocurrency trading, etc
Data processing, including data accessing and cleaning, and feature engineering.
Training-testing-trading, where DRL agent takes part in.
Performance monitoring, compare the performance of DRL agent with some baseline trading strategies.
With this pipeline, we are able to continuously produce dynamic market datasets.
3. Training-testing-trading pipeline:¶
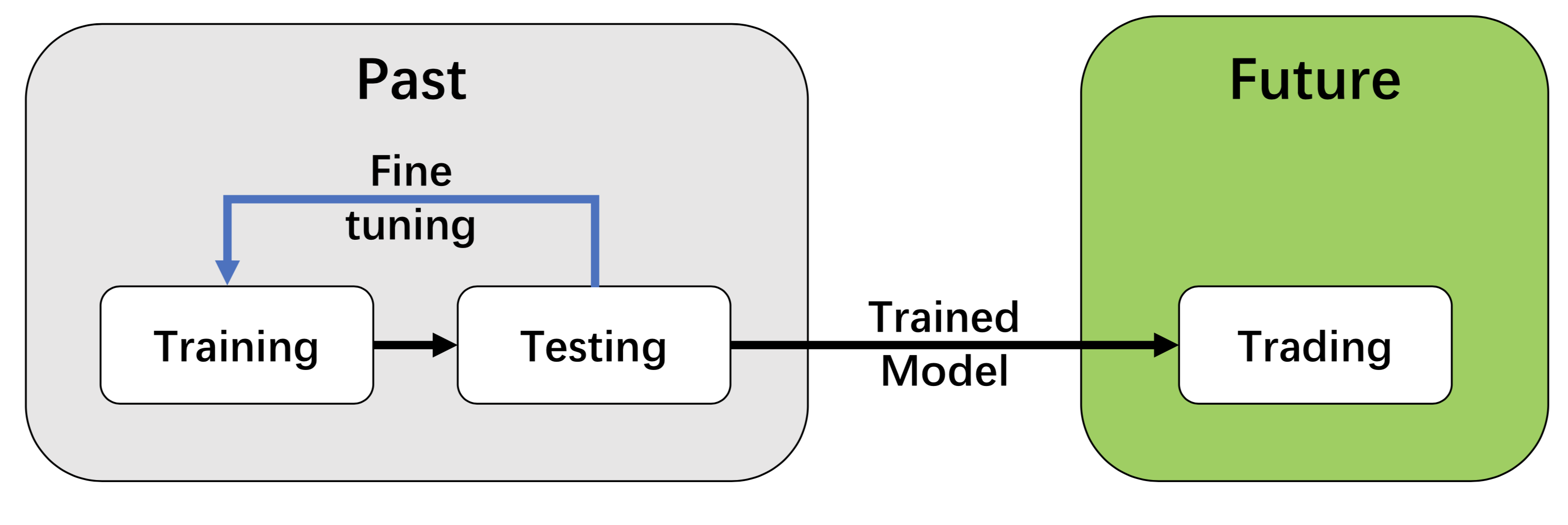
We employ a training-testing-trading pipeline that the DRL approach follows a standard end-to-end pipeline. The DRL agent is first trained in a training dataset and fined-tuned (adjusting hyperparameters) in a testing dataset. Then, backtest the agent (on historical dataset), or deploy in a paper/live trading market.
This pipeline address the information leakage problem by separating the training/testing-trading periods the agent never see the data in backtesting or paper/live trading stage.
And such a unified pipeline allows fair comparison among different algorithms.
4. Plug-and-play¶
In the development pipeline, we separate market environments from the data layer and the agent layer. Any DRL agent can be directly plugged into our environments, then will be trained and tested. Different agents can run on the same benchmark environment for fair comparisons. Several popular DRL libraries are supported, including ElegantRL, RLlib, and SB3.